

One of the most common modeling errors in machine learning is overfitting, an error that occurs when a certain function is too close or fits exactly with a particular set of data used for its training. But to understand this term and how to avoid it, let’s dig deeper and see its definition and how it can be detected and prevented.
✅Key definitions for understanding overfitting
Before we define overfitting, let’s review some critical definitions for understanding the concept:
- Generalization: a model generalization measures how good is the training for extracting and classifying data patterns or samples.
- Feature selection is about selecting the features that contribute the most in training the model, especially to avoid complexity or increment of the training time.
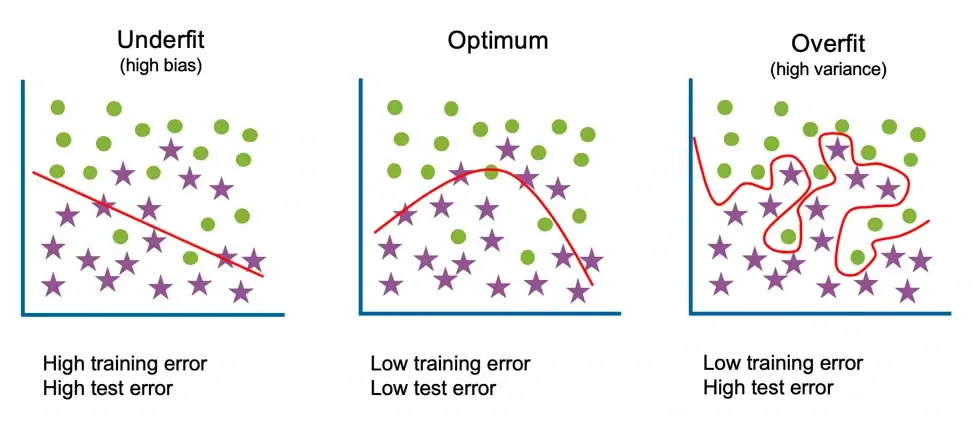
- The bias is the measure between the prediction and the target value. If a model is too simplified, the predicted value is far from the ground truth, which results in a higher bias.
- The variance is how much will the estimate change when given different training data. It measures the inconsistency of different predictions over varied datasets, so a higher variance will indicate that it’s a model without the ability to generalize (possibly with overfitting).
- Bias-variance trade-off measures the tension between the error introduced by the previous two (bias and variance). Normally a linear model will have high bias and low variance, since it’s less complex and doesn’t have a lot of trainable parameters. But non-linear models or those with more complexity will tend to the opposite. The ideal and best scenario would be a model with an optimal balance between bias and variance.
- The test set is part of the training dataset that is set aside and used for checking if a model is overfitted. That way, if the training data has a low error rate and the test set has a high error rate, then it’s a signal that overfitting occurred.
Artificial Intelligence is revolutionizing the world of data: learn everything about ChatGPT 🤖
What is overfitting?
Overfitting in machine learning occurs when a statistical model fits or comes too close to its training data, introducing more bias and therefore not allowing it to perform accurately against other data that is unseen.
Generalization is what allows machine learning to make predictions and classify data, but if this training is too complex or too long, it can lead the model to memorize noise or irrelevant information within the dataset, which means the model will become overfitted and therefore unable to generalize any new data.
When a model is overfitted its whole purpose will be defeated, and therefore overfitting should be avoided or corrected when it occurs.
How to detect overfitting?
Unless you test the data, you won’t be able to detect overfitting, and if we think about an overfitted model one of its main characteristics is it can’t generalize datasets. Therefore, detecting an overfitted model can be done by testing it with unused data.
This process is normally done by segmenting the dataset, using the biggest part for training (normally around 80% of the total dataset) and the rest is used as a test set to check the models’ accuracy.
If the model performs better on the training set then it’s probably because it’s overfitted.
One very common technique for detecting overfitting is the K-fold cross-validation, where the data is split into K equally sized subsets (folds), using one as testing and the rest for training. But let’s see what more can you do to detect and prevent machine learning from becoming overfitted.

How to prevent overfitting?
Now that we know what overfitting is and how to detect it, let’s see what can be done to prevent it.
Use more data for training
When increasing the training data, the feature selection becomes more prominent and the model can recognize better the relationships between inputs and outputs. It makes it easier for the algorithm to minimize errors, and generalize new sets of data when tested.
Implement data augmentation
If using more data is too expensive, another option is to make the available data more diverse. Data augmentation is used for making data samples look slightly different each time they are processed, preventing the model from learning repeated information.
Another option with similar results to data augmentation is adding noise to the data. This can stabilize the model when done on the inputs, and also diversify it when applied to the outputs. But be careful with these techniques since they could lead to incorrect data, if not done correctly.
Simplify the data
Model complexity can be one of the reasons for overfitting, so by trying to use simplified models you could manage to reduce the probability of it happening. Some techniques for simplifying data can include reducing the parameter set or pruning decision trees, preventing it from growing to their full.
Apply ensemble learning
Ensembling consists in combining predictions from several models to produce a more optimal predictive model and prevent overfitting by acting upon the learning algorithms.
Commonly this process can be done by boosting or bagging:
- Boosting consists in combining several weak learners in a sequence so that each one learns from the mistakes of the other, getting as a result one strong learner with the best learning curve
- Bagging consists in training strong learners in parallel patterns, to finally combine them and optimize their predictions
Optimize and regulate the feature selection
This step is crucial since the more accurate the feature selection is, the more simplified the model will be. Too many features could lead to unnecessary complexity, and the more complex a model is the higher the possibility of it overfitting.
Avoiding overfitting is all about trial and error, since you can’t know it’s happening without testing. So remember that validation is very important in machine learning and data science in general.
And if you feel like learning much more, this Master’s in Data Science can provide you with enough knowledge and tools to become an expert in Machine and Deep Learning and learn your way into the market with the best business tips and strategies.

